


Для чего это нужно?
- Сегментация потребителей
- Определение групп связанных признаков (при кластеризации переменных)
Как это работает?
На входе анализа – набор переменных, описывающих совокупность респондентов. Метод работает с интервальными (например, возраст, доход, оценка степени согласия по 10-балльной шкале и т.д.) и дихотомическими переменными (например, пол, наличие/отсутствие руководящих функций) переменными.
Совокупность из n значений по всем n переменным определяет положение объекта в неком n-мерном пространстве. Исходя из этих координат определяются расстояния между объектами. Для расчёта расстояний чаще всего используется Евклидово расстояние, однако метод расчёта расстояний может варьироваться в зависимости от специфики данных.
Метод группирует схожие (расположенные близко друг к другу) объекты, в результате чего формируется набор из нескольких кластеров.
Число кластеров может определяться автоматически на основе выбранного критерия либо выбираться вручную исследователем с учётом теоретических предпосылок и понимания предмета исследования.
Что получаем в итоге?
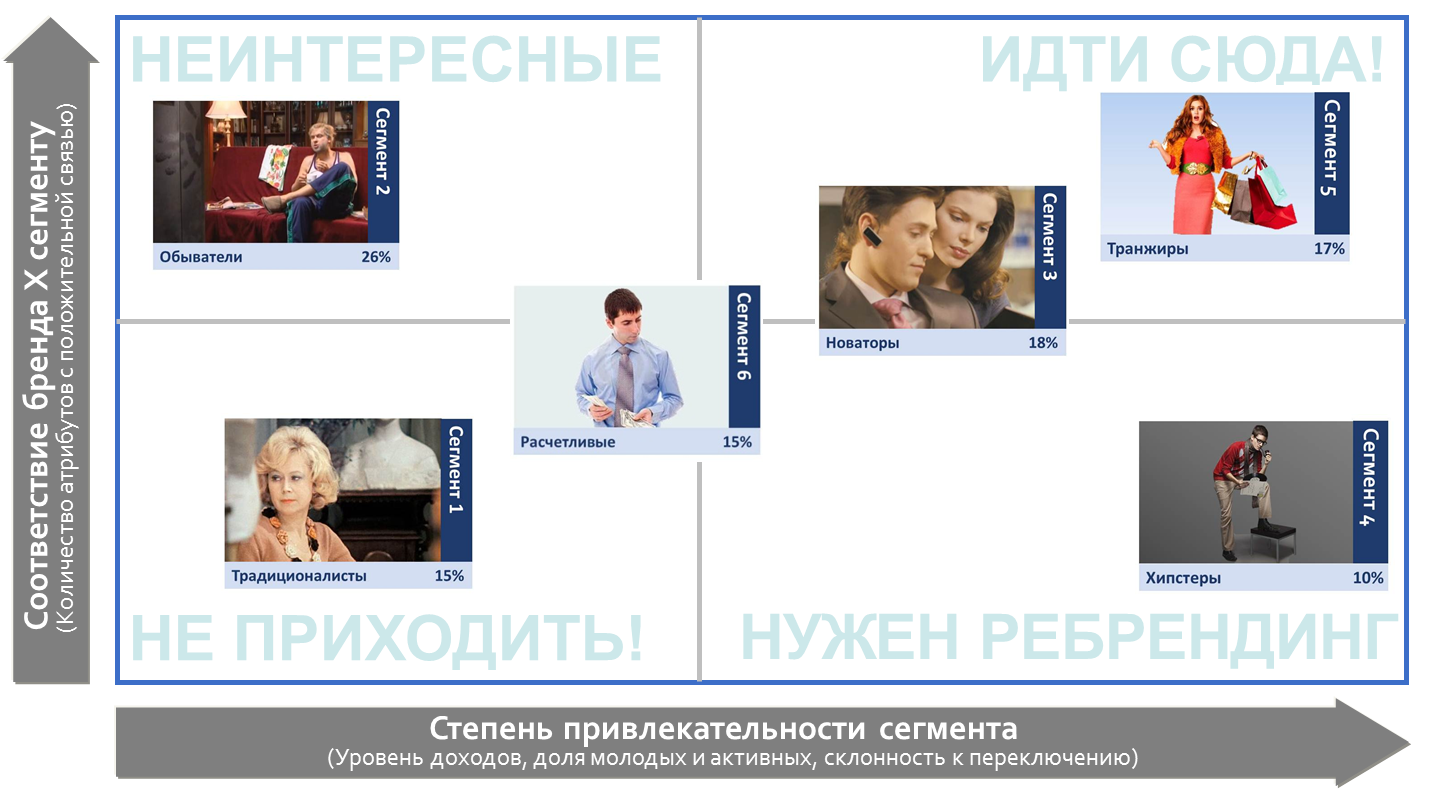
На выходе – набор кластеров/сегментов.
Каждый сегмент описывается средними по кластеру значениями переменных. С помощью этих данных можно выделить характерные особенности сегментов, их отличительные черты.
При хорошем кластерном решении дисперсия значений переменных внутри кластера должна быть минимальной (т.е. респонденты внутри кластера однородны), а дисперсия между кластерами максимальна (т.е. респонденты из одного кластера не похожи на респондентов из другого).
Каковы преимущества метода?
Хорошее кластерное решение даёт яркие и чётко различающиеся сегменты.
На основе данных кластерного анализа можно выбирать разные стратегии работы с каждым из сегментов.
Тем не менее, т.к. метод основан на расстояниях между объектами, он не работает с типами переменных, которые не дают возможности рассчитать эти расстояния – категориальными и порядковыми. В случае с такими типами переменных для проведения сегментации рекомендуется использовать CHAID-анализ.
Как еще больше узнать о методе?
- Подпишитесь на нашу страницу в Facebook или Вконтакте и следите за нашими открытыми лекциями и выступлениями на конференциях. Если это научные конференции, как правило, участие в них свободное.
- Если вы студент или выпускник НИУ ВШЭ, постарайтесь попасть на лекцию к Марку Шафиру в рамках курса «Современные методы анализа данных».
- Закажите нам исследование с использованием этого метода.